教程1:ASA Pipeline:实验数据解码全流程¶
目标:学习如何使用 canns.analyzer.data 跑通实验数据的 ASA pipeline,
包括 time/spatial TDA、相位解码、CohoMap/CohoSpace、PathCompare 与 FR/FRM。
结构:
数据格式与准备
嵌入 spike trains
TDA + 解码
Cohomology Decoding + CohoMap / PathCompare
CohoSpace / CohoScore
FR Heatmap / FRM
Note
本教程仅展示 Python 层调用。若需交互式操作,可使用 python -m canns.pipeline.asa_gui
或 canns-gui 启动 GUI(后续章节详述)。
0. ASA 能做什么¶
ASA(Attractor Structure Analyzer)面向 实验科学家 ,将群体神经活动 (spike / firing rate)与行为轨迹(x, y, t)串成一条可复现的分析链路, 用于发现与解释隐藏的低维结构(ring / torus 等 attractor manifold)。
常见科研问题:
群体活动中是否存在 环 / 环面 等拓扑结构?(time TDA)
若按空间位置聚合为
r_i(x),空间表征本身是否具有稳定拓扑?(spatial TDA)若存在结构:相位坐标如何映射到真实轨迹?(CohoMap)
解码轨迹是否与真实路径对齐?(PathCompare)
哪些神经元最“集中/选择性”?(CohoScore + CohoSpace)
如何快速浏览群体活动与单元放电图?(FR / FRM)
ASA 的workflow 核心流程依赖 TDA 与 cocycle decoding,但 FR/FRM 可独立使用。
其中 time TDA 的输入点云是随时间变化的群体活动 r(t),适合继续做 decode、
CohoMap、CohoSpace 与 PathCompare;spatial TDA 则先把活动按动物位置 bin 成
r_i(x),再对空间 bin 构成的点云做 persistent homology,适合检查 Fig.4C 风格的
空间表征 barcode。
Input (ASA .npz: spike, x, y, t)
→ embed_spike_trains (可选)
→ Time TDA on r(t) (persistent homology + cocycles)
→ Decode v2 (coords / coordsbox / times_box)
→ CohoMap / PathCompare / CohoSpace / CohoScore
→ FR / FRM
Optional branch:
→ Spatial embedding r_i(x)
→ Spatial TDA barcode
1. 数据格式与准备¶
ASA 输入为 .npz,最少包含:
spike:神经活动(list-of-arrays / dict /(T, N))x、y:轨迹坐标((T,))t:时间戳((T,))
本教程使用内置 load_grid_data 演示。你也可以替换为自己的实验数据。
[7]:
from canns.data.loaders import load_grid_data
grid_data = load_grid_data()
print(f"Keys: {list(grid_data.keys())}")
print(f"t: {grid_data['t'].shape}, x: {grid_data['x'].shape}, y: {grid_data['y'].shape}")
print(f"spike type: {type(grid_data['spike'])}")
Loaded grid_1: 172 neurons
Position data available: 238700 time points
Keys: ['spike', 't', 'x', 'y']
t: (238700,), x: (238700,), y: (238700,)
spike type: <class 'numpy.ndarray'>
2. 嵌入 spike trains¶
当 spike 是 list-of-arrays / dict 时,需要使用
embed_spike_trains 转换为 (T, N) 连续矩阵。
[8]:
from canns.analyzer import data
spike_cfg = data.SpikeEmbeddingConfig(
smooth=True,
speed_filter=False,
min_speed=2.5,
)
spikes, xx, yy, tt = data.embed_spike_trains(grid_data, config=spike_cfg)
print(f"Embedded spikes: {spikes.shape}")
Embedded spikes: (238700, 172)
3. TDA + 解码¶
使用 tda_vis 获取持续同调结果,再用
decode_circular_coordinates_multi 解码相位轨迹。
3.1 TDA 原理:从点云到拓扑¶
在 ASA 中,每个时间点的群体活动向量 A[t, :] 被视为一个 N 维空间中的点。这样,
T 个时间点就形成一个点云。
直觉:如果网络存在吸引子/流形(例如 bump 在环上移动),这些点会聚集在低维结构附近 (ring / torus),而不是填满整个 N 维空间。
Note
若启用 speed_filter,低速时间点会被过滤。此时 **解码输出**会提供 times_box,
用于将相位对齐回原始 x/y/t 轨迹。
3.2 ASA 中的 TDA 五步流程¶
时间下采样 (
num_times)选择最活跃时间点 (
active_times)PCA 降维 (
dim)点云去噪 / 代表性采样 (
k,n_points,metric)计算 Persistent Homology (
maxdim,coeff)
实践建议:
active_times通常取下采样后时间点数量的 5%–20%先用
maxdim=1判断环结构,再考虑maxdim=2查看 torus
3.3 从 cocycle 到角度:为什么能解码出相位¶
ripser 在 PH 计算中会返回 cocycle(上同调代表元)。ASA 的解码过程可理解为:
cocycle 提供“沿着环一圈相位累积一次”的结构信息
通过最小二乘重建一个相位函数
f(再映射为θ = 2π f)在全时序上用群体活动加权得到
θ(t)
重要提醒:解码得到的 θ 是吸引子相位,并不等同于真实 x/y。真实物理含义
需要通过 CohoMap 可视化其在轨迹中的展开方式。
3.4 Shuffle 的作用(显著性检验)¶
当你怀疑结构可能来自噪声或采样伪影时,可以开启 shuffle:
在破坏拓扑结构但保留部分统计量的 surrogate 数据上重复 TDA
若真实 barcode 明显长于 shuffle 上界,结构更可信
Note
Shuffle 代价很高,建议先跑主 TDA,再做少量 shuffle 作为 sanity check。
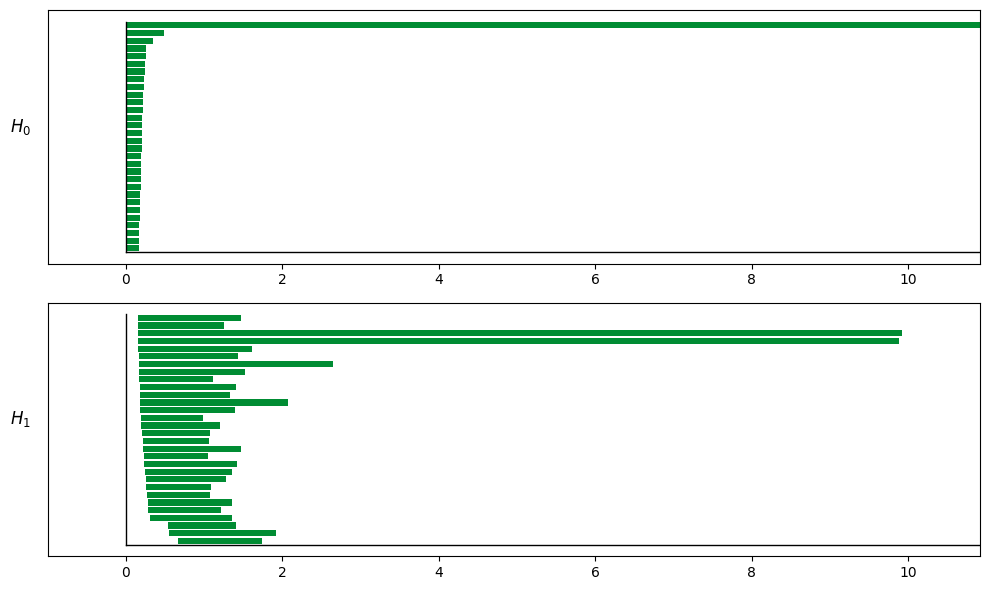
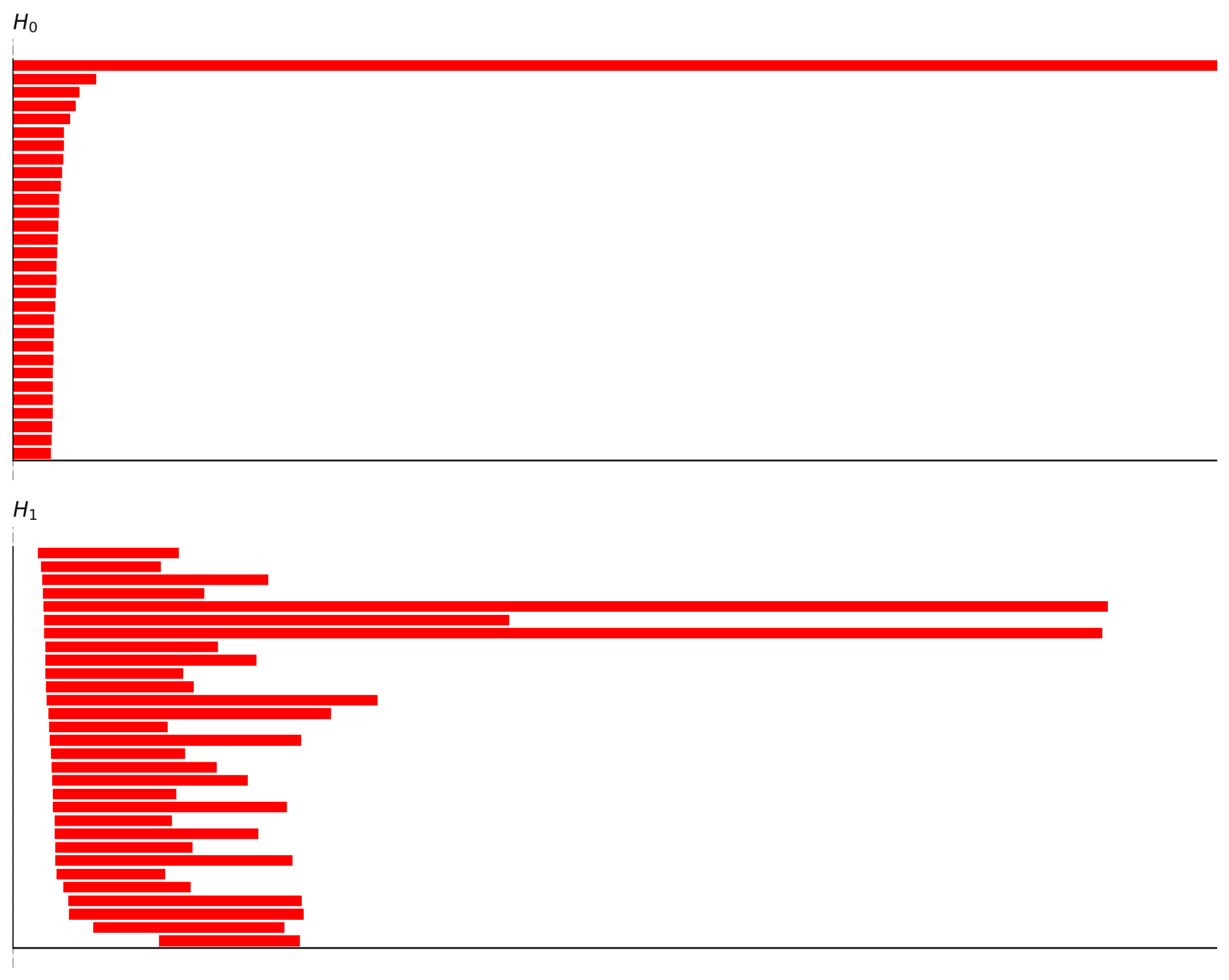
3.5 如何读 barcode(何时需要 shuffle)¶
在 TDA/barcode.png 中,关键是识别“显著长条”。
H0(连通分支):最终应收敛到 1 条主分支(Betti0≈1)
H1(1 维洞/环):ring 常见 1 条明显长条(Betti1≈1)
H2(2 维空腔):torus 常见 1 条明显长条(Betti2≈1)
为什么 torus 的 (H0, H1, H2) 常见为 (1, 2, 1):
H1=2:存在两条独立环方向(可理解为“经线/纬线”)
H2=1:存在一个二维“壳”包围空腔
Important
若你怀疑存在 torus,请将 maxdim 设为 2 才能看到 H2。
否则只会看到 H1,容易误判为简单 ring。
经验判断与 workflow:
第一轮:先跑主 TDA(不 shuffle),若 H1/H2 信号很强,直接进入 decode + CohoMap
第二轮(可选):当结构不够清晰或噪声较重时,再做少量 shuffle 作为 sanity check
Note
Shuffle 不是默认步骤:它更像 “只有在怀疑时才启用” 的验证手段。
3.6 TDA 参数指南¶
Preprocess / embed:
res, dt:时间分箱,需与t单位一致sigma:平滑尺度(越大越平滑,但会模糊快变化)speed_filter, min_speed:grid cell 常用;启用后请依赖times_box对齐
TDA 核心参数:
num_times:时间下采样步长(越大越快,但可能丢细节)active_times:选取最活跃时间点数(太小不稳;太大更慢/更噪)dim:PCA 维度(常见起点 6–12)k, n_points, nbs:去噪采样与距离构建(影响速度与稳定性)metric:推荐cosine(对幅值不敏感)maxdim:建议先用1,确认结构后再尝试2coeff:有限域系数(ASA 默认 47)
Shuffle:
先跑主 TDA 再做少量 shuffle
不建议默认大规模 shuffle(代价高)
[9]:
from canns.analyzer.visualization import PlotConfigs
# TDA
TDA_cfg = data.TDAConfig(maxdim=1, do_shuffle=False, show=True, progress_bar=True)
persistence = data.tda_vis(embed_data=spikes, config=TDA_cfg)
# Decode
grid_data_embedded = dict(grid_data)
grid_data_embedded["spike"] = spikes
decoding = data.decode_circular_coordinates_multi(
persistence_result=persistence,
spike_data=grid_data_embedded,
num_circ=2,
)
print(decoding.keys())
Computing persistent homology for real data...
Completed H1 computation: 100%|██████████| 718201/718201 [00:05<00:00, 134504.22columns/s]
dict_keys(['coords', 'coordsbox', 'times', 'times_box', 'centcosall', 'centsinall'])
解码输出关键字段
coords:解码相位(T' × K)coordsbox:用于对齐的相位(T' × K)times_box:对齐索引(T')
4. Cohomology Decoding:从 cocycle 到相位¶
很多人卡在“为什么能解码出角度 θ(t)”。ASA 的做法是:
ripser 返回 cocycle(上同调代表元)
选取接近
death的阈值(常用birth + 0.99*(death-birth))解一个最小二乘问题,把“边上的相位差”还原为“点上的相位”
将
f ∈ [0,1)映射到θ = 2π f用群体活动加权扩展到全时间点,得到
θ(t)
直觉总结:
cocycle 给出“绕洞一圈相位累积一次”的参照系
群体活动把参照系推广到所有时间点
4.1 相位与物理空间:注意点¶
θ(t)是 吸引子相位,不是x/y的直接替代在 torus 场景,
θ1/θ2更像“折叠后的周期相位”正确解释方式:用 CohoMap 将相位投影回真实轨迹,观察展开方式
对齐要点:
使用
times_box对齐解码结果与x/y/tcoords与coordsbox的差异用于处理 speed filter 与采样对齐
对齐示例(使用 times_box):
t_use, x_use, y_use, coords_use, _ = data.align_coords_to_position_2d(
t_full=np.asarray(grid_data["t"]).ravel(),
x_full=np.asarray(grid_data["x"]).ravel(),
y_full=np.asarray(grid_data["y"]).ravel(),
coords2=np.asarray(decoding["coords"]),
use_box=True,
times_box=decoding.get("times_box", None),
interp_to_full=True,
)
coords_use = data.apply_angle_scale(coords_use, "rad")
4.2 CohoMap 与 PathCompare¶
cohomap将 decoded phase 按真实x/y位置分箱,计算每个空间 bin 内的 circular-mean phaseplot_cohomap绘制 EcohoMap;当解码结果包含多个 circular coordinate 时,会自动显示多张 phase mapplot_cohomap_scatter_multi仍保留为 legacy scatter 可视化plot_path_compare_1d/plot_path_compare_2d对齐真实路径与解码路径
[ ]:
import numpy as np
from canns.analyzer.visualization import PlotConfigs
# CohoMap / EcohoMap
cohomap_cfg = PlotConfigs.cohomap(show=True)
cohomap_result = data.cohomap(
decoding_result=decoding,
position_data={"x": grid_data["x"], "y": grid_data["y"], "t": grid_data["t"]},
)
data.plot_cohomap(cohomap_result, config=cohomap_cfg)
# PathCompare
coords = np.asarray(decoding.get("coords"))
t_use, x_use, y_use, coords_use, _ = data.align_coords_to_position_2d(
t_full=np.asarray(grid_data["t"]).ravel()[200:260],
x_full=np.asarray(grid_data["x"]).ravel()[200:260],
y_full=np.asarray(grid_data["y"]).ravel()[200:260],
coords2=coords,
use_box=True,
times_box=decoding.get("times_box", None),
interp_to_full=True,
)
coords_use = data.apply_angle_scale(coords_use, "rad")
path_cfg = PlotConfigs.path_compare_2d(show=True)
data.plot_path_compare_2d(x_use, y_use, coords_use, config=path_cfg)
5. CohoSpace / CohoScore¶
CohoSpace 用于查看神经元在相位空间上的偏好分布。当前推荐的 EcohoSpace 会把神经元活动 按 decoded phase space 分箱,得到每个神经元在 coho-space 上的 firing-rate map 与 phase center; scatter 版本仍保留,适合 1D 或 legacy 可视化。
.. note:: 对应示例脚本可参考: ``examples/experimental_data_analysis/cohospace_example.py``、 ``examples/experimental_data_analysis/cohospace_scatter1d.py``、 ``examples/experimental_data_analysis/cohospace_scatter2d.py`` 与 ``examples/experimental_data_analysis/cohospace_phase_centers_example.py``。[ ]:
coords = np.asarray(decoding.get("coords"))
cohospace_result = data.cohospace(
coords=coords[:, :2],
spikes=spikes,
times=decoding.get("times_box", None),
bins=51,
smooth_sigma=1.0,
)
cohospace_cfg = PlotConfigs.cohospace_neuron_2d(show=True)
data.plot_cohospace_skewed(
cohospace_result,
neuron_id=130,
config=cohospace_cfg,
)
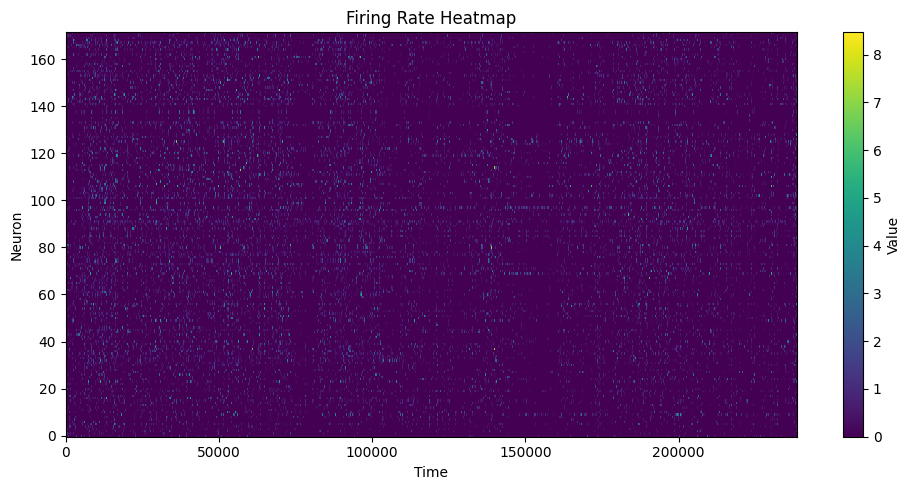
6. FR Heatmap / FRM¶
compute_fr_heatmap_matrix:群体活动热图compute_frm:单神经元空间放电图
[6]:
# FR Heatmap
heatmap = data.compute_fr_heatmap_matrix(spikes, transpose=True)
heatmap_cfg = PlotConfigs.fr_heatmap(show=True)
data.save_fr_heatmap_png(heatmap, config=heatmap_cfg)
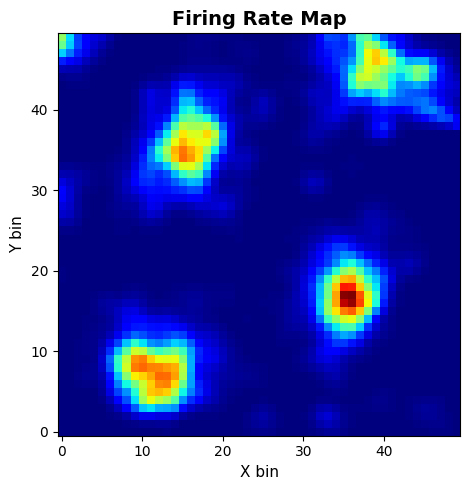
# FRM
frm_res = data.compute_frm(
spikes,
grid_data["x"],
grid_data["y"],
neuron_id=130,
bins=50,
min_occupancy=1,
smoothing=True,
sigma=1.0,
nan_for_empty=True,
)
frm_cfg = PlotConfigs.frm(show=True)
data.plot_frm(frm_res.frm, config=frm_cfg, dpi=200)
可视化示例¶
下面的 EcohoMap 与 EcohoSpace 示例使用 grid 1 数据生成,用来展示当前推荐的 coho 系列输出形式。
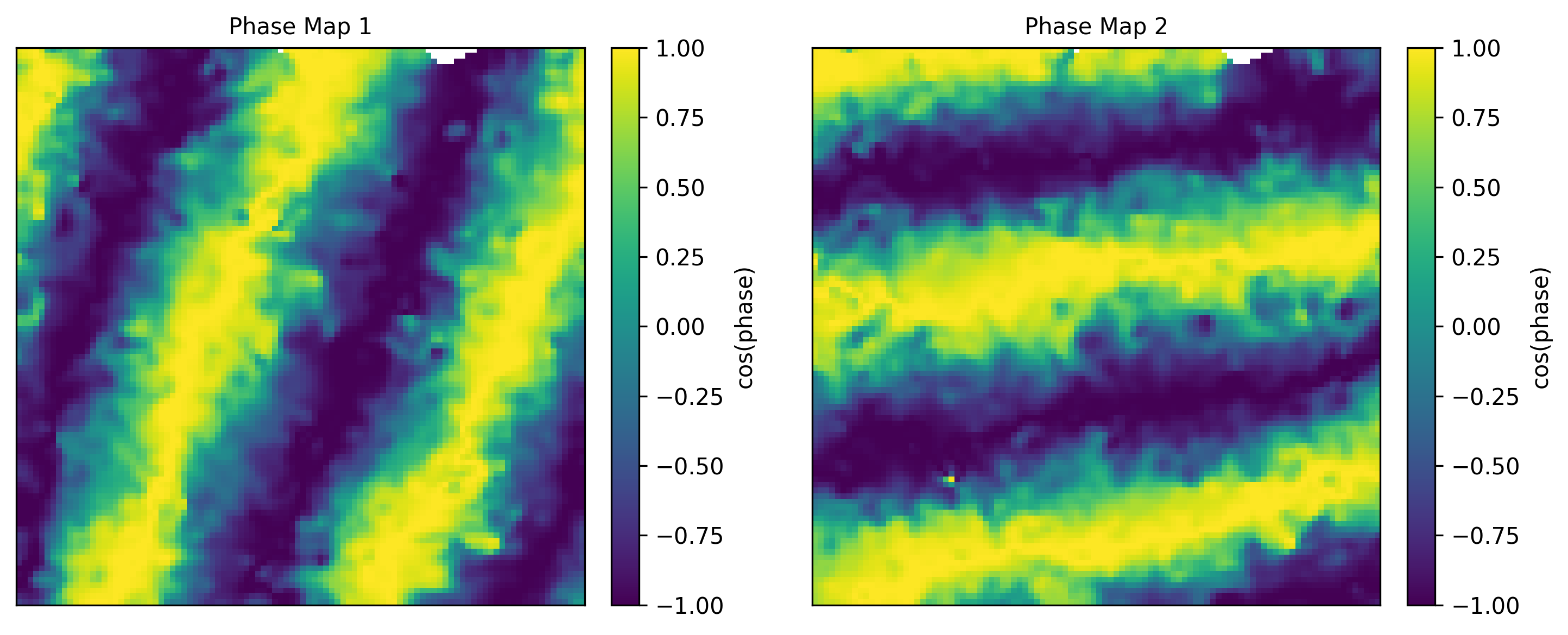
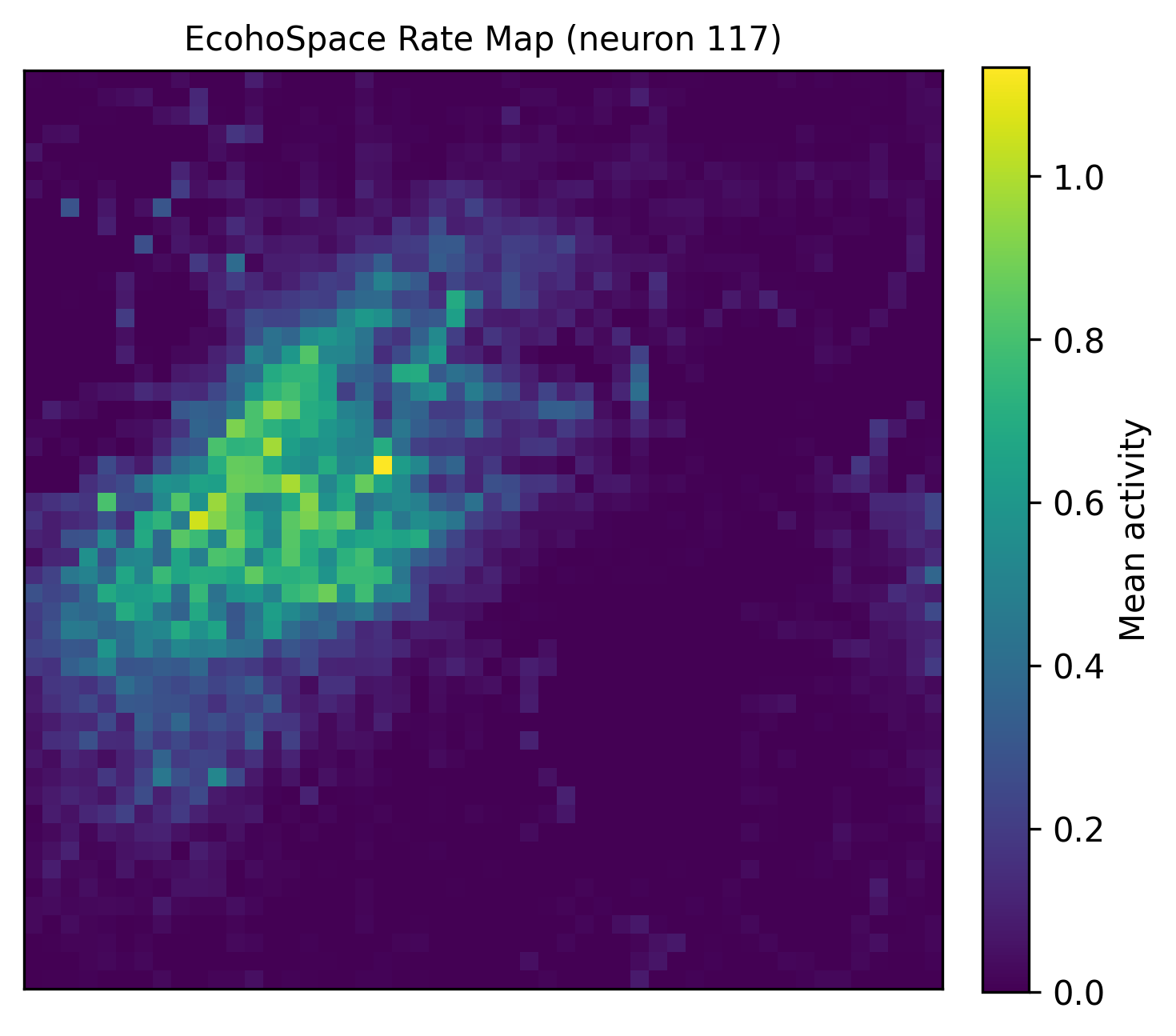
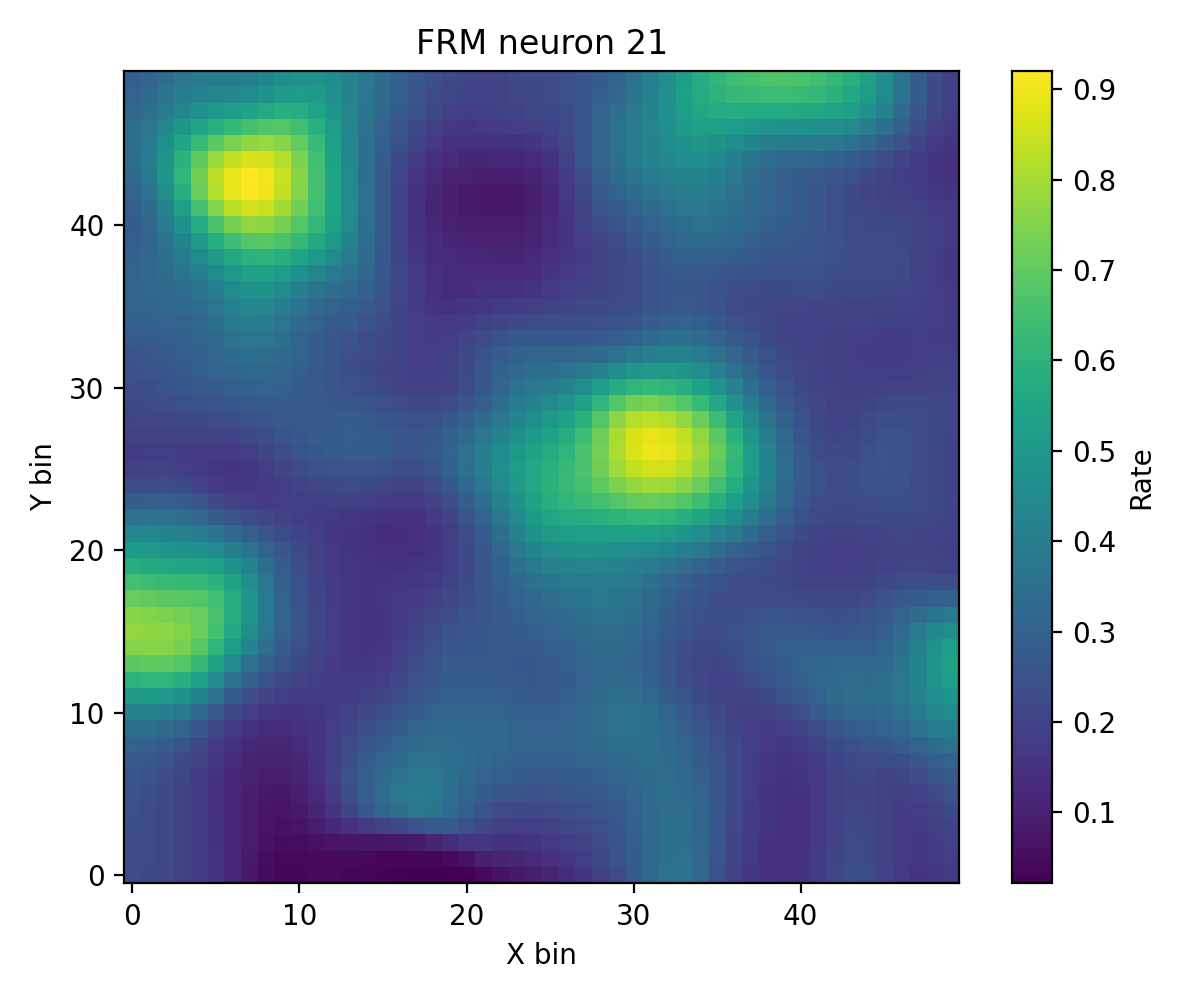
相关示例脚本¶
examples/experimental_data_analysis/tda_vis.pyexamples/experimental_data_analysis/tda_null_model_compare.pyexamples/experimental_data_analysis/spatial_tda_from_asa.pyexamples/experimental_data_analysis/cohomap_example.pyexamples/experimental_data_analysis/cohomap_scatter.pyexamples/experimental_data_analysis/cohospace_example.pyexamples/experimental_data_analysis/cohospace_scatter1d.pyexamples/experimental_data_analysis/cohospace_scatter2d.pyexamples/experimental_data_analysis/cohospace_phase_centers_example.pyexamples/experimental_data_analysis/auto_grid_threshold_example.pyexamples/experimental_data_analysis/subcluster_grid_cells_asa.pyexamples/experimental_data_analysis/path_compare1d.pyexamples/experimental_data_analysis/path_compare2d.pyexamples/experimental_data_analysis/firing_rate_heatmap.pyexamples/experimental_data_analysis/firing_field_map.pyexamples/cell_classification